Overview¶
Significant effort has been put into developing record-linkage algorithms using deterministic, probabilistic, or machine learning methods, or a combination of approaches [1] [2] [3]. EHRcorral takes a probabilistic approach, wherein certain fields are weighted based on their match-level, which is determined using numerical or lexical analysis in the context of two records or the entire set of records. A composite probability of two records matching is calculated and if the probability is above a threshold value the records are linked. Several pre-processing steps are often taken to reduce the computational requirements and attempt to increase the sensitivity and specificity of the algorithm.
Precedents¶
Purely deterministic models, which attempt to find identical values in certain fields, are unideal for many healthcare data sets [4]. Keying errors, misspellings, and transpositions of first name and last name are all too common in EHRs [5] [6], and some institutions are only able to record minimal identifying information about patients, such as is often the case with transient, homeless, and under-served populations. This makes it difficult to identify a field or fields which can reliably be matched exactly across records.
Machine learning algorithms, such as neural networks, can be used for matching, with pros and cons compared to other approaches [7]. However, while machine learning is becoming more common in many fields as computational units become cheaper, most of these algorithms require some method of training in order to identify a “pattern” and develop a specific algorithm to be applied on future records for linkage. This training might entail feeding in a large data set where record links have already been identified, or training the algorithm as it is developed.
A probabilistic method can run immediately on a data set without training data and identify record linkages with surprising sensitivity and specificity when the right settings are used. The OX-LINK system, which was developed to match 58 million healthcare records spanning from the 1960s to the ‘90s, achieved a false positive rate of 0.20%—0.30% and a false negative rate from 1.0%—3.0% on several hundred thousand records [8]. This system uses a combination of probabilistic, weighted matching, lexical analysis, phonemic blocking, and manual review. Recent publications also suggest that high sensitivity can be achieved with probabilistic methods, even in the context of error-prone data.
The approach taken here is influenced in large part by the methods of OX-LINK. Subsequent improvements to such probabilistic techniques have been incorporated, as well.
Phonemic Tokenization¶
Phonemic name compression, indexing, or tokenization schemes use phonetics to approximately represent a word or name. There are several common name compression schemes in wide use, including Soundex, NYSIIS, metaphone, and double metaphone, which appear here in chronological order according to their date of creation [9] [10]. The purpose of name compression in record linkage is to allow for a potential name match when the spelling of two names disagree but the phonetics are identical. For example, the Soundex code for Catie and Caity are both C300, although their spelling is different.
Soundex is the oldest method here, developed in the early 1900s and used to aid the U.S.A. Census Bureau [11]. It is computationally efficient and included in several modern databases for fuzzy name matching for that reason, but its shortcomings are quite obvious when non-Anglo-Saxan names are used and in other scenarios. Continuing the example in the previous paragraph, the Soundex code for Katie is K300, although it sounds identical to both Catie and Caity, which both have the code C300. After stripping vowels and other characters in certain situations, Soundex only looks at the initial part of a name.
NYSIIS was developed in the 1970s and is used by the New York State Department of Health and Criminal Justice Services. Unlike Soundex, vowels are not dropped and codes are not truncated to just four characters. For example, the NYSIIS encoding of Jonathan is JANATAN. This characteristic leads to improvements in a number of areas, and the algorithm is purported to better handle phonemes that occur in Hispanic and some European names. The NYSIIS codes for Catie, Caity, and Katie are all CATY. The improvement can be seen here since NYSIIS correctly identifies the same code for these phonetically identical names.
Metaphone, and then double metaphone, are the most recent phonemic compressions available in EHRcorral [13] [12]. Metaphone was first published in 1990 and is the first algorithm here to consider the sequences of letters and sounds rather than just individual characters. It also performs its compression based on the entire name, not a truncated or stripped version. Double metaphone was released ten years after metaphone, and particularly turns its attention toward accounting for combinations of sounds that are not present in the english language. This makes double metaphone suitable for compression of english or anglicized names of a variety of origins, including Chinese, European, Spanish, Greek, French, Italian, and more. It is the most robust algorithm not only for that reason, but also because it produces two encodings per name: a primary encoding and a secondary encoding. The metaphone codes for Catie, Caity, and Katie are all KT. Double metaphone produces just one encoding (again, KT) and drops the secondary encoding since this is a phonetically simple name. If we consider the name Katherine, metaphone produces KORN while double metaphone generates two encodings, KORN, KTRN.
Phonemic compressions have been widely used to quickly identify similar names for record linkage. They can quickly identify similar names and exclude dissimilar ones, reducing the time to find matches, and they can improve false positive/negative rates by eliminating unnecessary matches. They are important to understand in the context of Record Blocking.
Record Blocking¶
Record blocking is a technique used to eliminate probabilistic matching
between records that clearly do not match based on some field, such as last
name [14] [15]. If every record
has to be checked against every other record for a probabilistic match there
are 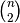 checks that must occur. For n=1,000,000 records,
this would require 499,999,500,000 (499 trillion) record-to-record
comparisons. If every comparison takes just 1 microsecond, it would still
take over 5 days for the matching process to complete. However, if we were
able to limit record-to-record comparisons to groups (i.e. blocks) of records
that have the possibility of matching and ignore other record-to-record
combinations, the time to completion could be greatly reduced.
checks that must occur. For n=1,000,000 records,
this would require 499,999,500,000 (499 trillion) record-to-record
comparisons. If every comparison takes just 1 microsecond, it would still
take over 5 days for the matching process to complete. However, if we were
able to limit record-to-record comparisons to groups (i.e. blocks) of records
that have the possibility of matching and ignore other record-to-record
combinations, the time to completion could be greatly reduced.
By default, EHRcorral blocks data into groups by the phonemic compression of the current surname plus the first initial of the forename. Other blocking techniques group by phonemic compression of the forename or current surname, or by birth month or year. A combinatory approach can be taken, as well, blocking by both current surname and birth year, and then by sex and birth month. By probabilistically checking only records in the same block, the time until the algorithm finishes is greatly reduced if the average block size is manageable. Blocking by phonemic compression has the advantage of eliminating checks between two names that have similar spelling but different pronunciations, potentially eliminating false positives that might match based on word-distance measures alone. On the other hand, if the phonemic compression algorithm is inaccurate (as we saw with Caity and Katie using Soundex), potential matches are discarded, increasing the false negative rate.
Soundex, NYSIIS, and metaphone all generate a single encoding, while the more robust double metaphone generates two encodings. In the case of double metaphone both encodings are used, effectively creating larger block sizes. This can lead to a significant increase in computation time, depending on the data set. Therefore, the first initial of the forename is also used to then decrease the block size. This also helps reduce the size of blocks for very common surnames, such as Smith, which occurs at a rate of about 1% (or 10,000 for every one million) in the United States of America.
Exploding Data¶
Exploding the data set refers to the process of generating additional Records from each Record by combining, switching, or expanding fields. The purpose of exploding the data set is to mitigate the effect of certain data entry errors or scenarios encountered in EHRs, such as the transposition of first name and middle name, or the entry of a nickname in a name field. This process is used in conjunction with blocking in order to increase the potential matches of a record that might have these errors [8].
Consider a Record for a man named Bill Taft Robinson:
Initially, blocking would be performed by taking the phonemic compression of the current surname plus the first initial of the forename. The primary double metaphone compression of Robinson is RPNSN, and adding on the first initial of the forename would put this record in block RPNSNB. When this record is exploded, it will get the following additional blocking groups:
- RPNSNT, using the first initial of the mid-forename
- RPNSNW, using William in place of Bill for the forename since Bill is a common nickname for William in the english language.
This makes this Record available for probabilistic matching within three blocking groups. Therefore, if Bill Taft Robinson has another Record under William Taft Robinson, a potential match can be found with this Record. Note that the blocking group is only used to determine which Records are checked. It does not modify the forename, nor does it insert William in place of Bill.
A standard set of names and their nicknames is not yet included with EHRcorral, but in the future one can be supplied to customize the explosion to names from a different region. For example, instead of Bill and William, when dealing with records containing Hispanic and Western European names perhaps the European name Elizabeth should also be considered as Isabel, the accepted Spanish version of Elizabeth, for blocking purposes.
Matching¶
The matching that EHRcorral does is heavily based on the Oxford Record Linkage System (OX-Link) [8]. It takes a number of name and non-name fields and determines the similarities between two respective records. Based on the similarity weight calculated for each individual field, an aggregate similarity for the two records is determined.
EHRcorral cycles through every record to build a square symmetric similarity matrix. Thus, the similarity between any two records can be determined by looking at the matrix. By thresholding the similarity matrix, one can create a link between records with similarities above the threshold.
Similarity Measures¶
EHRcorral separates record similarity into two sections: name fields and non-name fields. Name fields alone have a high degree of accuracy in determining the similarity of two records [16] [17]. Thus, EHRcorral heavily weights matching based on names and uses the non-name fields for fine-tuning.
However, there are many types of entry errors [18].
- character insertion: Richard
Ricthard
- character omission: Sullivan
- character substitution: Robert
- character transposition: 55414
- gender misclassification: M
To deal with the first four errors, EHRcorral converts all characters to lowercase and uses the damerau-levenshtein edit distance measurement on most of its data fields [7]. Thus, if any of those errors occur, the similarity between the two fields compared is still high. To avoid the issue of gender misclassification as best as possible, EHRcorral focuses on sex in comparisons. Further work may be done in this area to handle better gender misclassification in the future. Birth date and postal code are converted to character fields to handle all of the character errors above and better understand the similarity of the fields between records.
The name fields have complex similarity calculations. These fields have the potential for a different type of transposition error than other fields. One may enter a forename as a mid-forename or vice versa. This can happen with current and birth surname as well. To account for this, EHRcorral checks both forename or surname fields in the second record when comparing it with the respective field from the first and takes the one with the highest similarity. This has the benefit of handling the case where a surname is changed, e.g. in marriage, much better. Once the similarity is determined, EHRcorral checks whether a given surname compression (see Phonemic Tokenization for compression details) is common or rare or checks whether a given forename first letter is common or rare. The compression is used with surnames to negate potentially unique entry errors impacting the determination. The forename is less significant in determining the similarity of two records, so using just the first letter saves time computationally and avoids most entry errors while remaining relatively accurate. With the determination of a name being common or rare, the similarity is scaled accordingly and a weight is assigned, which can go negative since very dissimilar names should lead records to be considered very dissimilar.
The address field requires a lot cleaning before a weight is calculated. First, both address fields are combined and put into lowercase. Then, all abbreviations for address suffixes (e.g. avenue) and designators (e .g. apartment) are found and standardized based on the abbreviations that the United States Postal Service uses [19]. After this, the first 12 characters of the address are compared as mentioned above to account for the different types of character entry errors. Address fields that only have a couple entry errors still have some similarity weight, but ones that have more differences are given zero weight. This accounts for people moving around without diminishing the similarity too much.
The comparison of the respective postal code and national identification fields are relatively simple. EHRcorral looks for exact matches and single differences in determining similarity for these fields. Here, outside of simple entry errors, any field that is not exactly the same is considered no match at all. This is due to the fact that similar values for these fields are only meaningful in as much as they represent entry errors. Like with address, there are no negative weights for the postal code due to the potential for moving. National identifications do not have negative weights because of the difficulty with getting consistent entry in this area.
The similarity between two sex fields is very simple. EHRcorral asks for single character sex identification. If they are the same, a small positive weight is returned. If they are not, then a large negative weight is returned. This is due to the fact that a different sex should render two records significantly less similar, but the same sex means very little for their similarity.
The date of birth field has a slightly more complex comparison. The year, month, and day are each compared separately using the damerau-levenshtein method of calculating edit distance to account for all of the character errors mentioned above. Then, the total similarity is summed with extra weight given to the year, since entry errors are less likely there (i.e. someone is more likely to recognize that 1972 was keyed in as 9172), and different generations will be reflected in this area to separate family members with common birth days. This field has a strong influence amongst the non-name fields since it should never change and matches do imply that records are quite similar. Like with sex, there is a strong negative weight for records that are strongly dissimilar, but there is also a strong positive weight for the reasons mentioned above.
The summing of the weights is relatively simple once all individual weights are calculated. An algebraic sum is divided by the total possible weight that a record could have (this will vary based on commonality of forenames and surnames). This returns a values between zero and one that determines the probability that two records are the same. Then, thresholding can be applied to make actual determinations.
Similarity Matrix¶
The similarity matrix is calculated by using the record similarity function described above. As EHRcorral cycles through each record, it looks at the respective blocks for that record (see Record Blocking for details) and determines similarities for each record within the respective blocks. Then, the accession number for each record is used to fill in the correct row with the similarities in the correct columns. All records that are not in the same block as the one being compared receive a zero similarity score. The similarity of any two records can be found by looking up their respective accession numbers and then look at either row and column combination.
Thresholding can be used to determine the linkage of records. EHRcorral leaves to the user the determination of which threshold is appropriate based on the particular data set on which they are using EHRcorral.
References
| [1] | Gu, Lifang, et al. “Record linkage: Current practice and future directions.” CSIRO Mathematical and Information Sciences Technical Report 3 (2003): 83. |
| [2] | Winkler, William E. “The state of record linkage and current research problems.” Statistical Research Division, US Census Bureau. 1999. |
| [3] | Morris, Genevieve et al. “Patient Identification And Matching Final Report”. HealthIT.gov. N.p., 2014. Web. 17 Sept. 2015. |
| [4] | Zhu, Ying, et al. “When to conduct probabilistic linkage vs. deterministic linkage? A simulation study.” Journal of Biomedical Informatics 56.C (2015): 80-86. |
| [5] | Just, B. H., et al. “Managing the integrity of patient identity in health information exchange.” Journal of AHIMA/American Health Information Management Association 80.7 (2009): 62-69. |
| [6] | Hogan, William R., and Michael M. Wagner. “Accuracy of data in computer-based patient records.” Journal of the American Medical Informatics Association 4.5 (1997): 342-355. institutions are only able to record minimal identifying information about |
| [7] | (1, 2) Bell, Glenn B., and Anil Sethi. “Matching records in a national medical patient index.” Communications of the ACM 44.9 (2001): 83-88. |
| [8] | (1, 2, 3) Gill, Leicester. “OX-LINK: the Oxford medical record linkage system.” (1997). |
| [9] | Alvey, W., and B. Jamerson. “Record Linkage Techniques—1997: Proceedings of an International Workshop and Exposition.” Washington, DC: Federal Committee on Statistical Methodology (1997). |
| [10] | Dolby, James L. “An algorithm for variable-length proper-name compression.” Information Technology and Libraries 3.4 (2013): 257-275. |
| [11] | Beider, Alexander, and Stephen Morse. “Phonetic Matching: A Better Soundex”. http://stevemorse.org. N.p., 2015. Web. 17 Oct. 2015. |
| [12] | Philips, Lawrence. “The double metaphone search algorithm.” C/C++ users journal 18.6 (2000): 38-43. |
| [13] | Lawrence, Philips. “Hanging on the metaphone.” Computer Language 7.12 (1990): 39-43. |
| [14] | Kelley, Robert Patrick. Blocking considerations for record linkage under conditions of uncertainty. Bureau of the Census, 1984. |
| [15] | Clark, D. E. “Practical introduction to record linkage for injury research.” Injury Prevention 10.3 (2004): 186-191. |
| [16] | Aldridge, Robert W., et al. “Accuracy of Probabilistic Linkage Using the Enhanced Matching System for Public Health and Epidemiological Studies.” PloS one 10.8 (2015): e0136179. |
| [17] | Weber, Susan C., et al. “A simple heuristic for blindfolded record linkage.” Journal of the American Medical Informatics Association 19.e1 (2012): e157-e161. |
| [18] | Theera-Ampornpunt, Nawanan, Boonchai Kijsanayotin, and Stuart M. Speedie. “Creating a large database test bed with typographical errors for record linkage evaluation.” AMIA... Annual Symposium proceedings/AMIA Symposium. AMIA Symposium. 2007. |
| [19] | United States Postal Service. “Appendix C”. Pe.usps.gov. N.p., 2015. Web. 4 Dec. 2015. |